
In unserem Blogpost zum Friction-Stir-Spot-Welding sind wir bereits auf den Prozess sowie die technologischen Herausforderungen eingegangen. In diesem Blogpost möchten wir die automatisierte Datenanalyse und Merkmalsextraktion näher betrachten.
Herausforderungen der Datenanalyse
Machine Learning ist dafür prädestiniert, Daten automatisiert zu analysieren und wichtige Merkmale zu extrahieren. Um die relevantesten Merkmale zu erkennen, ist jedoch eine Vielfalt von Daten notwendig. Insbesondere tiefe neuronale Netzwerke profitieren von einer vielfältigen Datenbasis und erzielen beeindruckende Resultate. Bei zu wenig Daten schneiden sie jedoch unterdurchschnittlich ab.
Hierbei kann es hilfreich sein, eine Vorauswahl relevanter Merkmale vorzunehmen, um bessere Ergebnisse zu erzielen. Oftmals ist jedoch nicht bekannt, welche Merkmale relevant sind und welche keinen Einfluss auf die Klassifikationsgüte des Netzwerkes haben. Insbesondere Zeitreihen beinhalten eine Vielzahl von Merkmalen, deren Analyse zeitaufwändig ist und schnell unübersichtlich werden kann.
Automatisierte Merkmalsextraktion
Für die automatische Extraktion von Merkmalen gibt es eine Vielzahl von Toolboxen. Eine, die sich als vielversprechend für die Analyse von Zeitreihen herauskristallisiert hat, ist die Python Toolbox tsFresh[1]. Durch die Anwendung etablierter Algorithmen aus verschiedenen Bereichen kann so ein breites Spektrum an Merkmalen erfasst werden.
Relevanzanalyse von Merkmalen
Eine Vielzahl von Merkmalen ist nicht immer hilfreich, um eine gute Künstliche Intelligenz (KI) zu trainieren. Eine Vorauswahl der besten Merkmale kann daher zu einer Leistungssteigerung der KI führen.
Am Beispiel des FSSW wird das Drehmoment verwendet, um Schweißungen in i.O. und n.i.O. zu klassifizieren. Als Algorithmus bietet sich hierfür ein Random Forest an [2]. Ein Random Forest ist ein effektiver maschineller Lernalgorithmus, der viele Entscheidungsbäume umfasst. Jeder Baum wird auf einer zufälligen Stichprobe der Daten trainiert und lernt anhand der Merkmale, die Daten in i.O. und n.i.O. zu unterteilen.
Nach dem Training kann automatisiert analysiert werden, welche Merkmale für die Entscheidungsfindung relevant sind. In Abbildung 1 sind die Top-5 Merkmale für die Entscheidungsfindung aufgezeigt. Insbesondere die Prozessdauer als auch das maximale Drehmoment haben den größten Einfluss auf die Klassifikation.
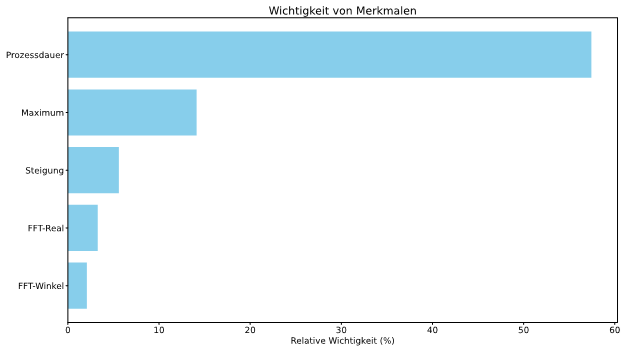
Durch den zunehmenden Verschleiß des Werkzeuges mit zunehmender Anzahl der Schweißungen, lässt sich diese anhand der Daten bestätigen. In Abbildung 2 werden stichprobenartig Aufzeichnungen dargestellt. Hierbei ist deutlich zu erkennen, dass sowohl die Prozessdauer als auch das maximale Drehmoment kontinuierlich abnehmen.
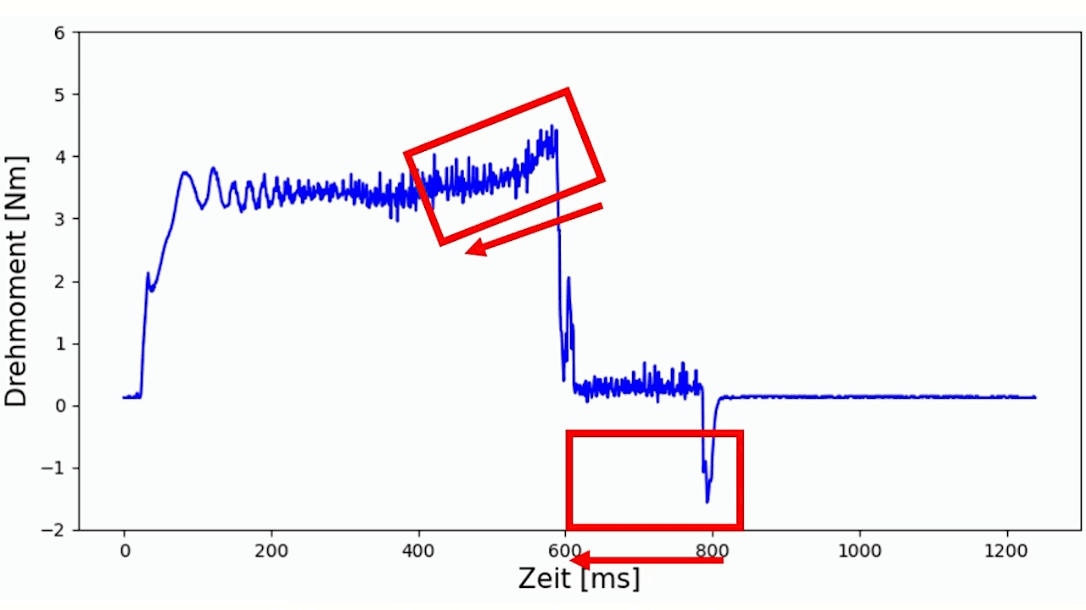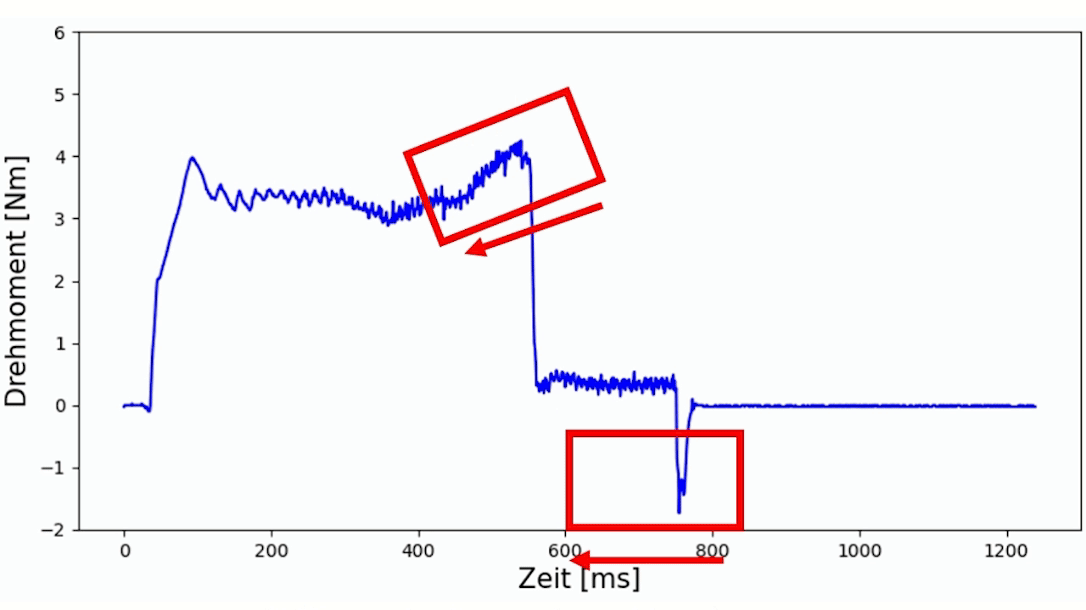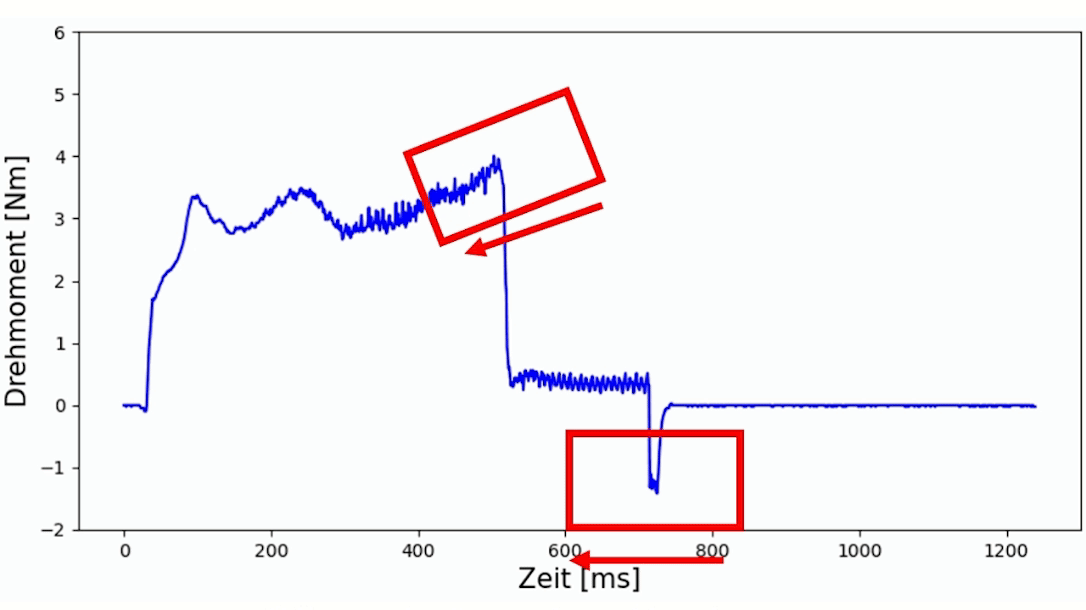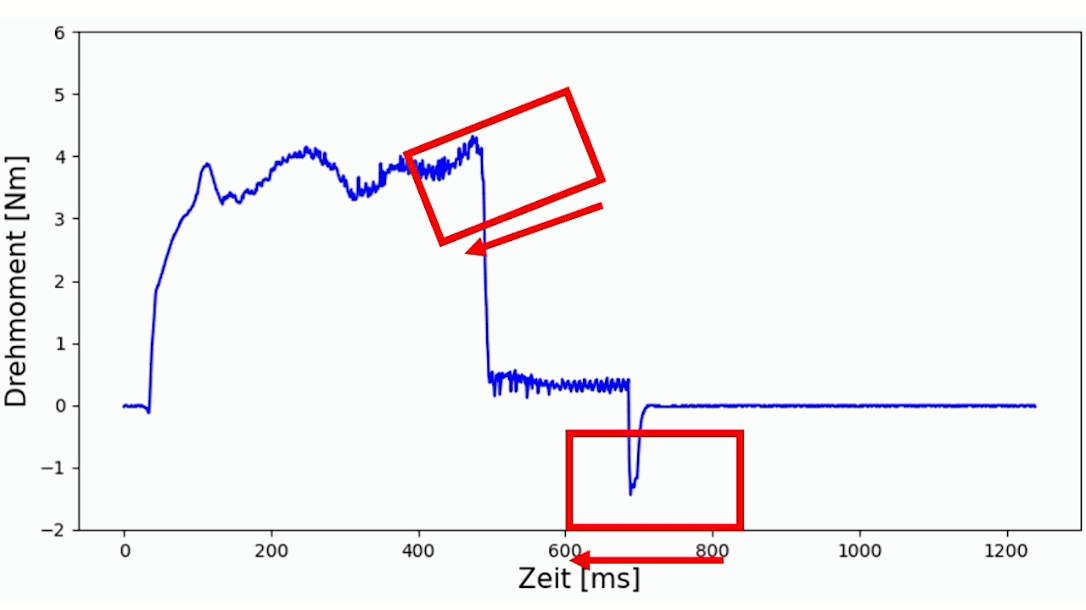
Klassifikation der Scherzugfestigkeit
Durch die zuvor durchgeführte Analyse können die Schweißungen anhand von zwei Merkmalen sowohl in i.O. als auch n.i.O. unterteilt werden. Anhand der vorhandenen Daten konnte so ein Klassifikator trainiert werden, der eine Trennung des 2D-Merkmalsraums vornimmt. Dies ist in Abbildung 3 dargestellt.
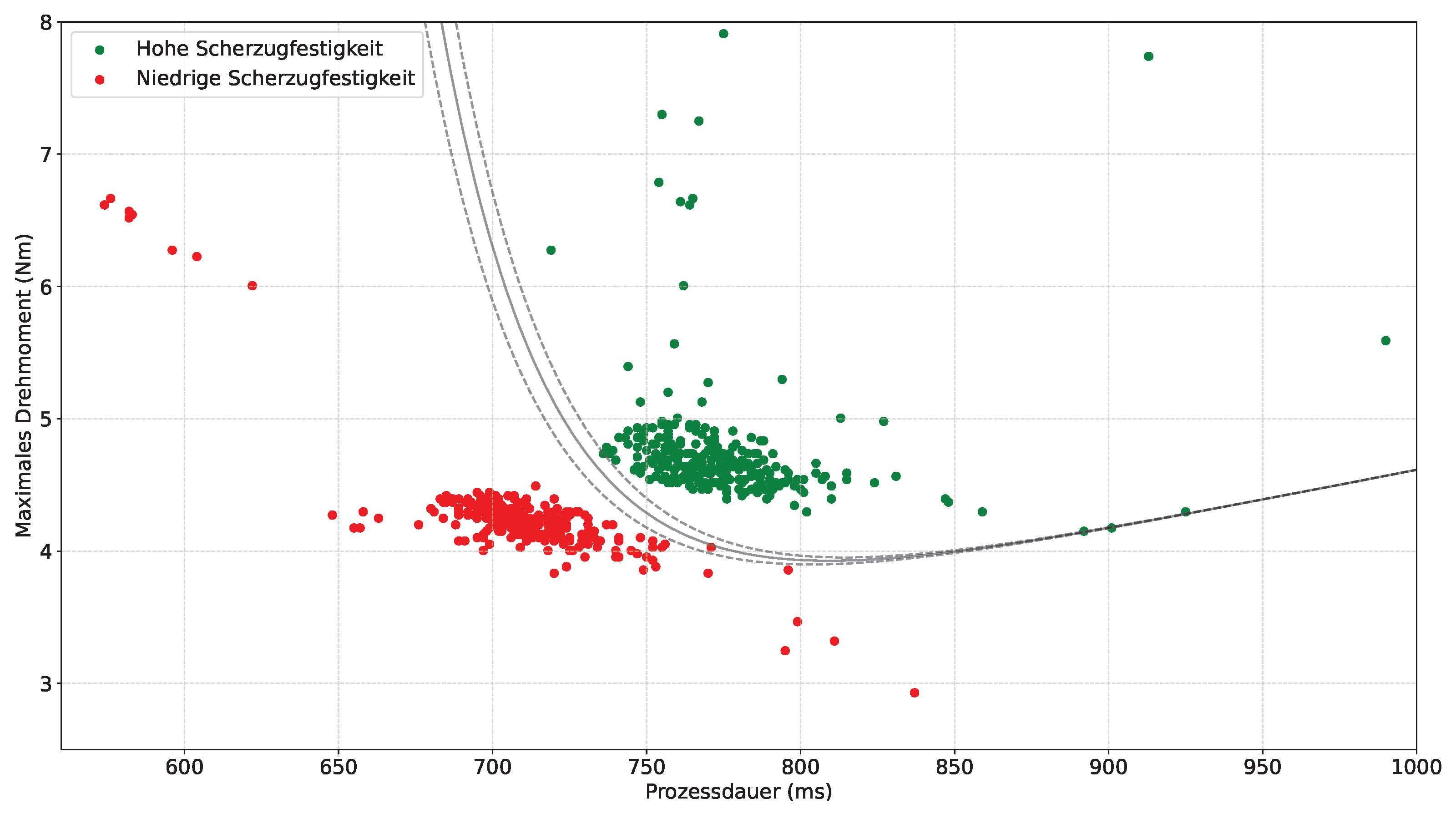
Zukünftige Schweißungen können dadurch automatisiert analysiert werden.
Beitrag von: M. Sc. Dominik Walther
Quellen
[1]Christ, M., Braun, N., Neuffer, J., and Kempa-Liehr A.W. (2018). Time Series FeatuRe Extraction on basis of Scalable Hypothesis tests (tsfresh — A Python package). Neurocomputing 307, p. 72-77
[2] Breiman, Leo. „Random forests.“ Machine learning 45 (2001): 5-32.


